
The development of software projects entails significant implementation and collaboration activities, typically supported by tools such as issue trackers, code review tools, and Version Control Systems. However, these tools only provide a partial view of the project and often lack of advanced querying mechanisms, thus hampering the analysis of the status of the project and endangering the decision making process on the best way to drive the development process. We present Gitana, a software project inspector able to import the activity of the different support tools into a single relational database, thus providing a central point to perform all kinds of cross-cutting analysis on the software project data.
This work has been accepted as al Original Software Publication (OSP) in the Science of Computer Programming Journal, you can find the official paper here or just continue reading.
Introduction
Software development processes are supported by a plethora of tools. Each tool helping to manage the complexity of a specific aspect of the project: source code is tracked by using Version Control Systems (VCSs) such as Git, development tasks are reported in issue trackers, and collaboration and coordination activities are normally developed in forums, mailing lists or chats. While all these tools store relevant information, they are actually silos that provide partial views of the project and lack of advanced query and data integration mechanisms. Thus, project managers often struggle to understand how projects perform, a must to make knowledgeable decisions about the development process
In this paper we present Gitana, a project inspector that analyzes the support tools used in software projects and imports the information in a relational database, thus providing a central point to perform all kinds of cross-cutting analysis on project data. The current version of the tool provides support to inspect Git repositories, Bugzilla/GitHub issue trackers, Eclipse forums and Slack instant messages. To ensure efficiency, Gitana comes with an incremental propagation mechanism that refreshes the database content with the latest modifications available on the data sources. The approach also incorporates exporters to enable further data analysis with third-party tools.
Problems and Background
Nowadays, software development activities are independently tracked and recorded in different tools. These tools have limited support for querying their internal data and typically rely on scripts (e.g., git commands) or APIs (e.g., the Bugzilla API) to do so. As a result, any advanced analysis of the data quickly becomes a hard and complex task. Especially to perform any data integration or combination operation involving more than one tool, as it is typically the case. As consequence, comparison of data from different projects is also challenging.
This situation limits the scope of existing research studies and tools devoted to understanding (and improving) software development (see our summary of all we have learned by mining GitHub plus some concerns [1]). For instance, GHTorrent [2] is a dataset only devoted to analyzing GitHub repositories, the work presented by Kahani et al. [3] target the analysis of Eclipse forums and Wang et al. [4] study the context of StackOverflow. Examples of more general tools are GrimoireLab and Kibble. They are similar to Gitana in their goals though they target a different user profile. In short, Gitana is the only one providing SQL-based access to the data which is a plus for users not familiar with Python libraries for data manipulation (e.g., Panda) and NoSQL storage engines (e.g., ElasticSearch) as required in those other tools. Therefore, we believe Gitana is especially useful for users (like, for instance, project managers) that want an easy way to explore the project data (and compare data across projects) by easily writing and running adhoc queries.
Software Framework and Architecture
We propose a unified access to the information made available by all support tools. Figure 1 depicts our approach. From a global conceptual schema for project-related concepts, we derived a relational database, which is then populated from a variety of partial sources through an incremental update mechanism. The database can be manually explored using standard SQL and/or used as the input for different kinds of deeper analysis processes such as complex network analysis and OLAP multidimensional analysis. Gitana architecture is divided into four main components (black-filled elements in Figure 1).
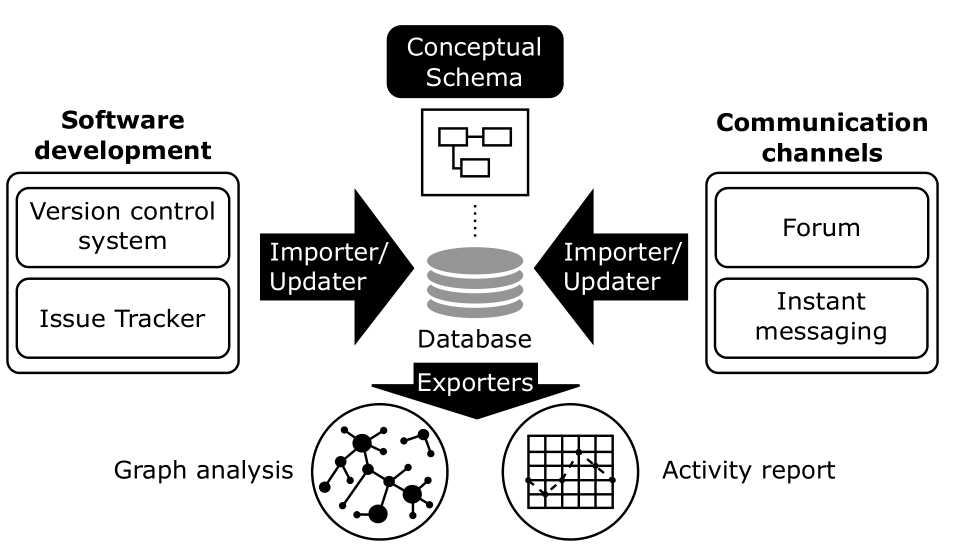
Figure 1: Our approach.
- The conceptual schema, which models the project activity. This schema is an extension of [5]. Full details are available here (see also additional explanations and examples)
- Importers, one for each source tool we cover. Gitana currently comes with importers for both development activities and communication channels. In particular, it includes importers for Git repositories [5], Bugzilla/GitHub issue-trackers, Eclipse forums, StackOverflow and Slack.
- Incremental Updater, in charge of keeping the information stored in the project tools aligned with the copy in our database while avoiding the need to start from scratch every time.
- Exporters, which provide data analysis features. Apart from direct SQL queries, Gitana also comes with graph and report generators to support other kinds of analysis.
Implementation and Evaluation
Gitana has been developed as a Python application. MySQL is used as database management system. Importers rely on Python libraries: Git-Python (to interact with Git), Python-bugzilla (for Bugzilla) and Pygithub (GitHub) and Py-stackexchange (StackOverflow). Selenium is used to automate the web browser interactions to collect Eclipse forum data. Data from Slack is obtained via Slacker, a Python interface for the Slack API.
The efficiency of the Gitana process has been evaluated on a set of GitHub open-source projects. In particular, we collected the 100 most popular (i.e., most starred) GitHub projects on September, 30th 2016 and defined four intervals based on their number of branches/commits. We then randomly selected three projects for each interval. We cloned the 12 projects and measured the execution time of the import process. Moreover, to evaluate the incremental update process, we pulled each project on December, 19th 2016 and measured the execution time of the update process, only for the branches previously imported. We ran the evaluation on a 2×2.5 GHz Intel Xeon processor with 48 GB of RAM. Table 1 shows the results. As can be seen, although the initial import can take some time, the incremental update takes over and minimizes the time of future imports.
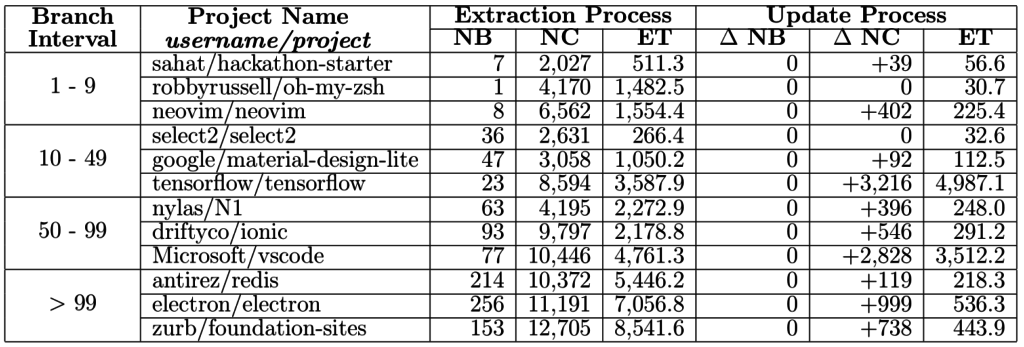
Table 1: Evaluation of the extraction process. NB = Number of Branches. NC = Number of commits. ET = Extraction time (secs)
Application Scenarios
Gitana has been successfully applied in a variety of scenarios (e.g., bus factor calculation [6] or maturity assessment [7]) and we continue to use it daily as our main software analysis tool. As an example, Gitana has been used in the context of a research-industry technology transfer with the Alternative Energies and Atomic Energy Commission organization (CEA) for the gamification of Papyrus [8], where Papyrus is an open-source modeling platform. Gitana was used to devise a gamification platform to promote and encourage developers to participate and contribute to the project, considering not only code contributions but also their participation in the forums/issues. A more recent example is the use of Gitana to evaluate the activity and monitor the sustainability of the Decidim project, a digital infrastructure for participatory democracy led by the Barcelona City Council.
References
[1] V. Cosentino, J. L. Cánovas Izquierdo, J. Cabot, A Systematic Mapping Study of Software Development with GitHub, IEEE Access 5 (2017) 7173–7192.
[2] G. Gousios, The GHTorrent Dataset and Tool Suite, in: Int. Conf. on Mining Software Repositories, 2013, pp. 233–236.
[3] N. Kahani, M. Bagherzadeh, J. Dingel, J. R. Cordy, The Problems with Eclipse Modeling Tools: A Topic Analysis of Eclipse Forums, in: Int. Conf. on Model Driven Engineering Languages and Systems, 2016, pp. 227–237.
[4] S. Wang, D. Lo, L. Jiang, An Empirical Study on Developer Interactions in StackOverflow, in: Symp. on Applied Computing, 2013, pp. 1019–1024.
[5] V. Cosentino, J. L. Cánovas Izquierdo, J. Cabot, Gitana: A SQL-Based Git Repository Inspector, in: Int. Conf. on Conceptual Modeling, 2015, pp. 329–343.
[6] V. Cosentino, J. L. Cánovas Izquierdo, J. Cabot, Assessing the Bus Factor of Git Repositories, in: Int. Conf. on Software Analysis, Evolution and Reengineering, 2015, pp. 499–503.
[7] J. L. Cánovas Izquierdo, V. Cosentino, J. Cabot, An Empirical Study on the Maturity of the Eclipse Modeling Ecosystem, in: Int. Conf. on Model Driven Engineering Languages and Systems, 2017, pp. 292–302.
[8] V. Cosentino, S. Gerard, J. Cabot, A Model-based Approach to Gamify the Learning of Modeling, in: Symp. on Conceptual Modeling Education, 2017, pp. 15–24.

Associate Professor at Universitat Oberta de Catalunya and researcher at SOM Research Team, in Barcelona, Spain, he likes investigating on how software is developed, in particular how open-source software is developed and how people collaboratively drives the creation process. He has been working mainly in the area of programming & domain-specific languages, modeling, modernization and model-driven engineering.
Looks great on paper but is not supported, not updated and does not works.
You’re right. As we honestly declare in our tool list page, the tool itself is not maintained anymore. The (conceptual) approach and ideas behind still do.
Just curious as why you decided not to continue to maintain/productize this. It would be a great tool for most enterprises looking to get empirical data from github.
I agree it is/was a promising tool but as a research team there is so much we can do it if there are no companies supporting the work. And at the time, we couldn’t find anybody interested.