
We (Valerio, Jordi and myself) have continued our meta-analysis of research papers on how software development practices are influenced by the use of a distributed social coding platform like GitHub (see our initial work in this area).
Our objective is to identify the quantity, topic and empirical methods used in these works to see what we have learned as a software community thanks to the large number of papers mining GitHub with the hope of extracting some useful information that can help improve software development.
To do this, we performed a systematic mapping study, which was conducted with four research questions and assessed 80 publications from 2009 to 2016.
Our study attested the high activity of research work around the field of Open Source collaboration, especially in the software domain, revealed a set of shortcomings and proposed some actions to mitigate them. We hope this work can also create the basis for additional studies on other collaborative activities (like book writing for instance) that are also moving to GitHub.
We provide a summary of our findings in this post. Full results have been published in the IEEE Access journal. Read them here (free for all, it’s an open access journal).
What topics/areas have been studied? What have we learned thanks to GitHub data?
The following table lists the main topics and areas that papers mining GitHub data focused on. We list a sample of the main findings reported by those papers. As you’ll see some of the findings are expected but others are more surprising. Let me emphasize again that these are NOT our findings but the findings of a large community of researchers working on this topic. Refer to the paper to go to the sources of each claim and get all the data you need to understand the context of the claim.
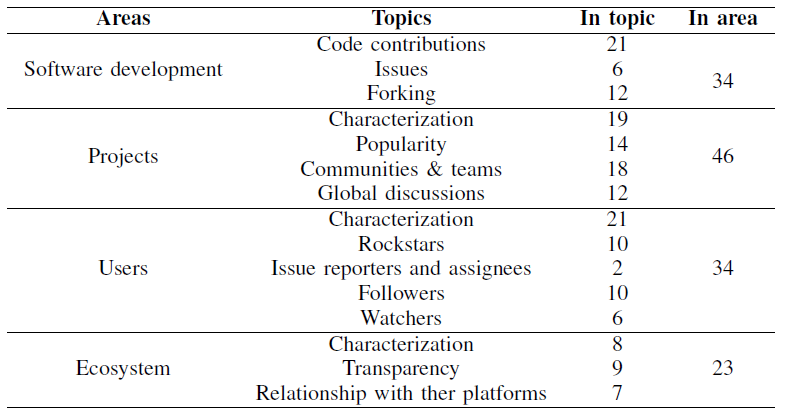
- On Development
- Code contributions
- Contributions are unevenly distributed across the project
- Few developers are responsible for a large set of code contributions
- Most contributions come in the form of direct code modifications
- Most pull requests are small (less than 20 lines), processed in less than 1 day and the discussion spans on average to 3 comments
- Importance of casual contributions: their contributions are becoming in fact rather common
- Technical (e.g., documentation or code length) and social (e.g., friendship or external contributions) factors are crucial to accept/reject pull requests
- Geographical factors also affects the acceptance of pull requests
- Pull request evaluation time depends on their complexity, author of the request or timing (e.g., sent out of business hours)
- Issues
- Issues tracker are scarcely used
- Few projects concentrate most of the issues
- Distribution of issues in a project: numerous when the project is created, stable when the project matures and pending issues always growing
- A small number of labels are used to tag issues
- Issue lifetime is generally stable
- The use of labels and @-mentions is effective in solving issues
- Forking
- Forking is unevenly distributed
- Forking is a good indicator of project liveliness
- Forks are mostly used to fix bugs
- Forking is beneficial for the project
- Forkability depends on several factors such as activity, publicity or community
- Code contributions
- Projects
- Characterization
- Most projects are personal
- Most projects choose not to benefit from GitHub features (beyond pure project hosting)
- Commercial projects also rely on GitHub
- Project domains mainly includes application and system software, documentation and libraries
- The top 5 project languages are JavaScript, Ruby, Python, Objective-C and Java
- User base and documentation keep the project alive
- Attracting and retaining contributors is key for project survival
- Popularity
- Few projects are popular
- The main benefit of project popularity is the attraction of new developers
- Project activity and project popularity is usually measured by the number of forks, start, followers and/or watchers
- Documentation as a factor for project popularity
- Fame of projects driven by organizations, which tend to be more popular than the ones owned by individuals
- Trends in programming languages and domain affect project popularity
- Communities and teams
- Small development teams are the rule
- Types of teams can be fluid, commercial, academic or stable
- Team diversity has a positive impact on the collaboration experience and productivity
- Community composition is usually difficult to measure
- Stability of core developers
- Few users become core developers
- Global discussions
- Most discussions revolve around code-center issues
- Long discussions have a negative effect
- Mood in discussions is generally neutral
- Barriers and enablers in discussions include having paid developers (barrier) and using label/mention mechanisms (enabler)
- Characterization
- Users
- Characterization
- A majority of users come from the United States
- GitHub is mainly driven by males and young developers
- Hobbyists as main citizens
- Approximately half of GitHub’s registered users work in private projects
- Indicators to assess the expertise, interest, and importance of users rely on main GitHub’s features (e.g., forking, project popularity, etc.)
- Sustained contributions and volume of activity of a user are considered as a signal of commitment to the project
- User productivity depends on factors such as the number of projects the user is involved and her commitment to the project
- Rockstars
- A rockstar, or popular user, is characterized by having a large number of followers, which are interested in how she codes, what projects she is following or working on
- Users become popular as they write more code and monitor more projects
- Rockstars play an important role in the project dissemination and attractiveness
- Issue reporters and assignees
- A vast majority of issue reporters are not active on code contributions, do not participate in any project and do not have followers, in addition, they often have an empty profile
- Followers
- Following is not mutual
- Reasons to follow include: to discover new projects and trends, for learning, socializing and collaborating as well as for implicit coordination and when looking for a job
- Following networks in GitHub fit the theory of the “six degrees of separation” in the “small world” phenomenon, meaning that any two people are on average separated by six intermediate connections
- Watchers
- Watching is generally used to assess the quality, popularity and worthwhile of a project
- Characterization
- Ecosystem
- Characterization
- Most ecosystems in GitHub revolve around one central project, whose purpose is to support software development, such as frameworks and libraries on which the other projects in the ecosystem rely on
- Popular ecosystems are usually interconnected
- Mutual evolution in linked ecosystems
- JavaScript, Java and Python dominate the ecosystems
- Transparency
- GitHub’s transparency helps in identifying user skills as well as enabling learning from the actions of others, facilitating the coordination between users in a given ecosystem and lowering the barriers for joining specific projects
- The transparency provided by GitHub can help in making sense of the project (or ecosystem) evolution over time
- Relationships with other platforms
- Existence of an ecosystem on the Internet for software developers which includes many platforms, such as GitHub, Twitter and StackOverflow, among others
- Twitter is used by developers to stay aware of industry changes, for learning, and for building relationships, thus it helps developers to keep up with the fast-paced development landscape
- StackOverflow is often used as a communication channel for project dissemination
- Characterization
How were these GitHub mining studies conducted?
We characterized the methodological aspects of the empirical process followed by the selected papers when inferring their results and take a critical look at them to evaluate how confident we can be about those results and how generalizable they might be.
What empirical methods have been used to reach the previous statements?
Regarding the details of the empirical methods used in the papers, we classified the selected papers according to:
- Type of methods employed for the analysis. This dimension can take four values, namely: (1) Metadata observation, when the work relies on the study of Github metadata; (2) surveys; (3) interviews; or (4) a mixture of methods. Other kinds of empirical methods are not added as dimensions since no instance of them were found.
- Sampling techniques used, which classifies the sampling techniques used to build the datasets out of GitHub (i.e., subsets of projects and users input of the analysis phase for the papers). This dimension can take three values, namely: (1) non-probability sampling, (2) probability sampling; or (3) no sampling.
- Self-awareness, which analyzes whether a paper reports on its own limitations (i.e., threats to validity).
The following figures summarize the results.
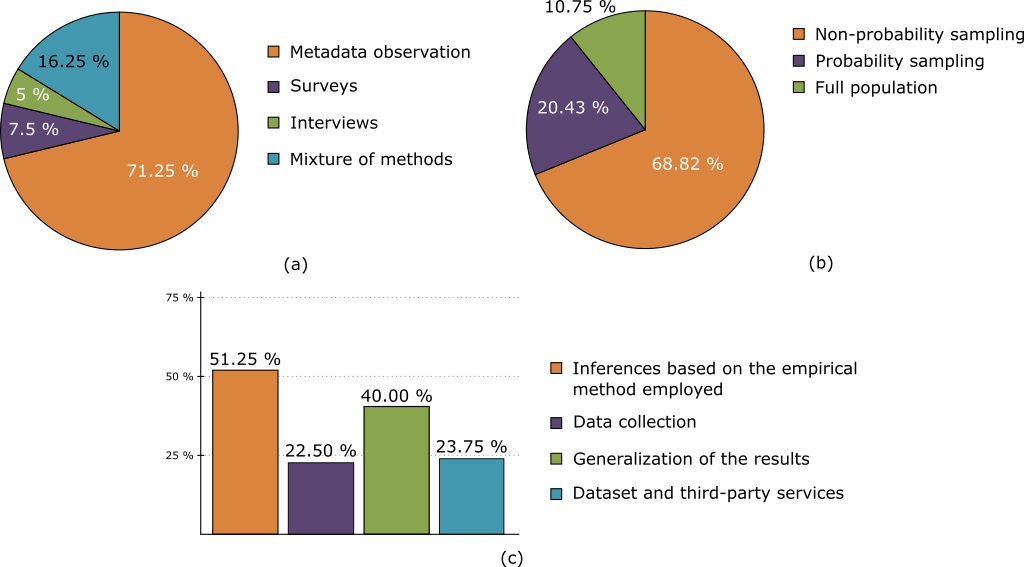
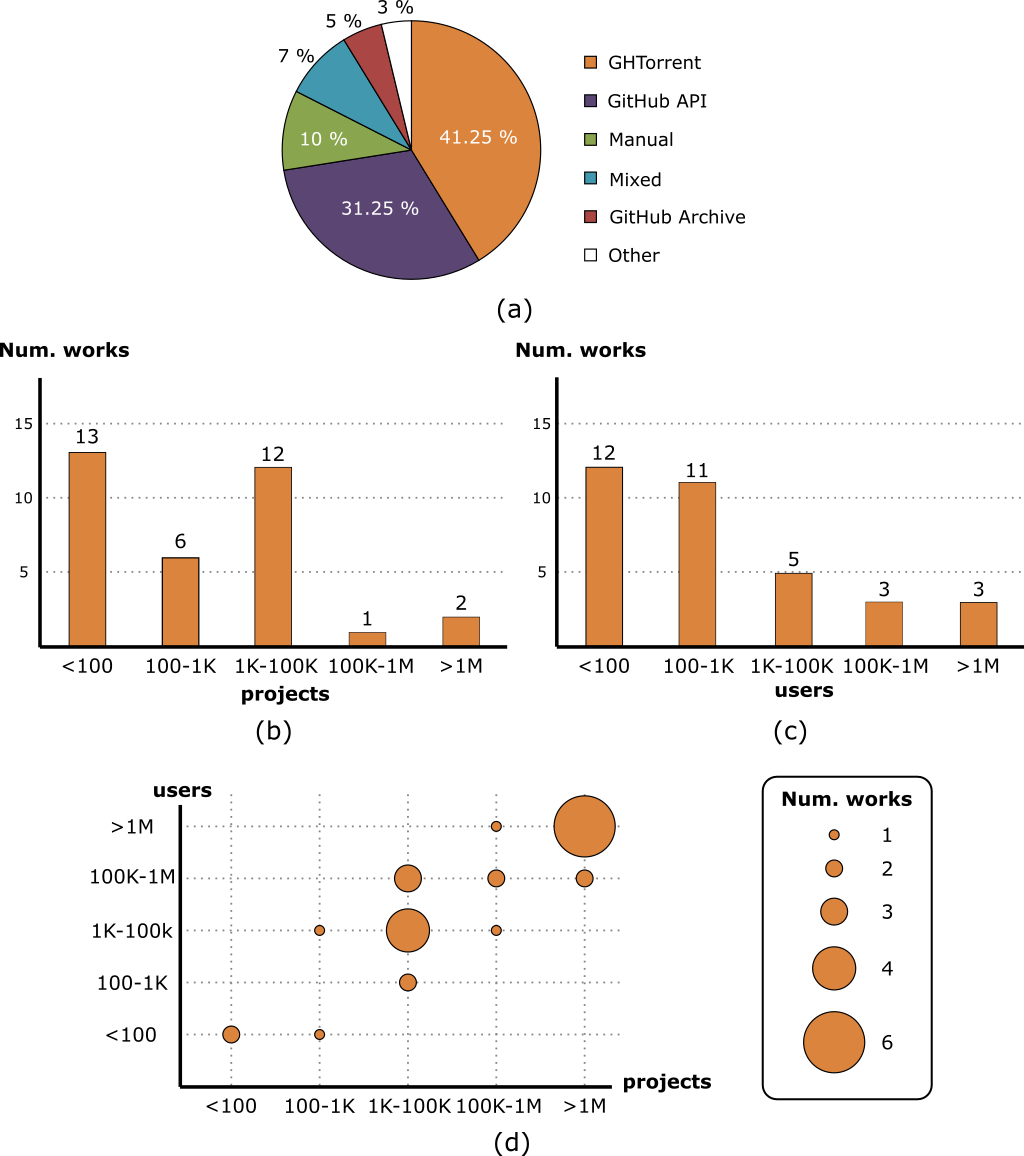
Which technologies have been used to extract and build datasets from GitHub?
Papers studying GitHub must first collect the data they need to analyze, which can either be created from scratch or by reusing existing datasets. We classified the selected papers according to:
- Data collection process, which reports on the tool/s used to retrieve the data. Currently there are six possible values for this dimension according to the tool used: (1) GHTorrent [80], (2) GitHub Archive, (3) GitHub API, (4) Others (e.g., BOA [101]), (5) manual approach and (6) a mixture of them.
- Dataset size and availability, which reports on the number of users and/or projects of the dataset used in the study, and indicates whether the dataset is provided together with the publication. This may help to evaluate the replicability of the work.
The following figures summarize the results.
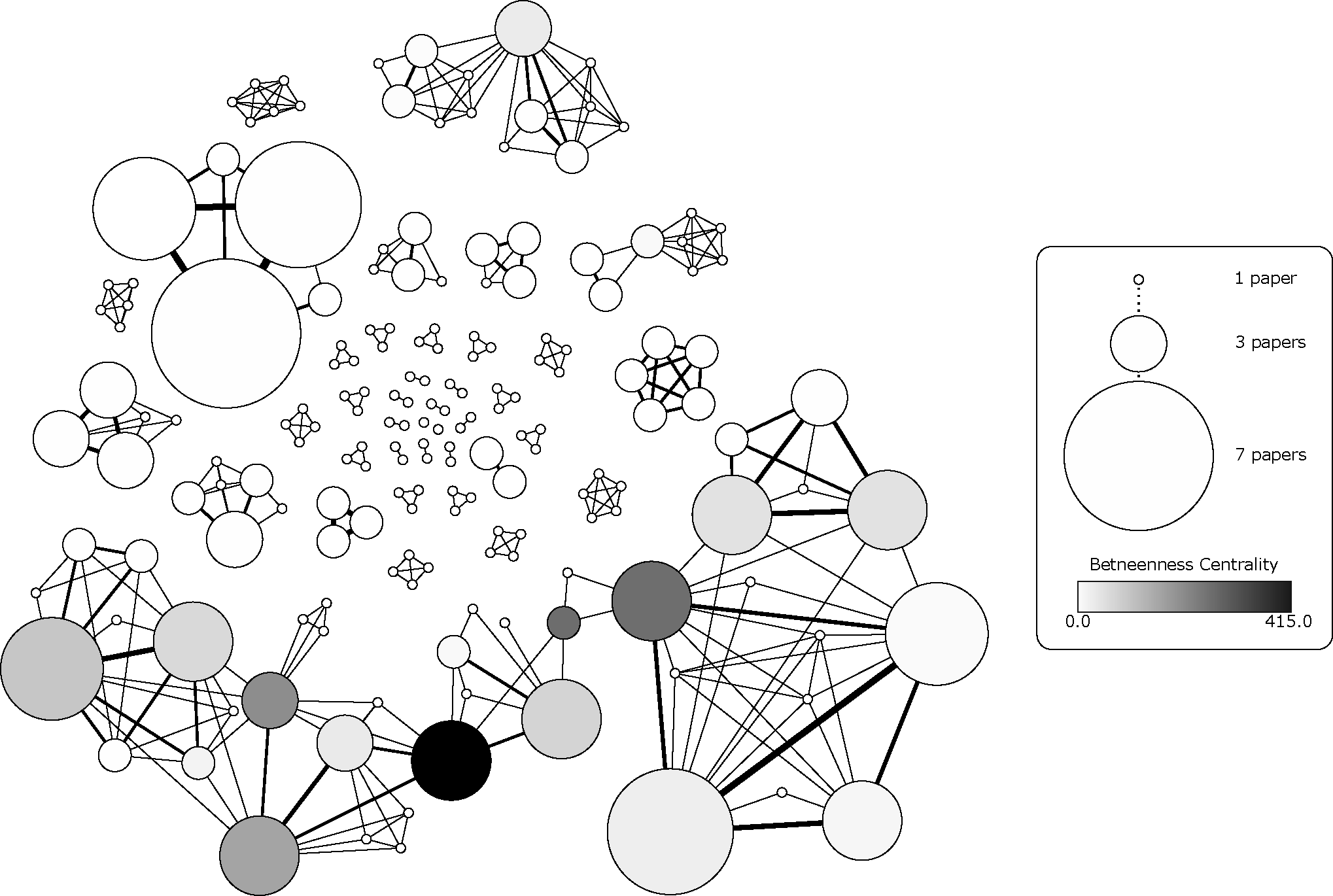
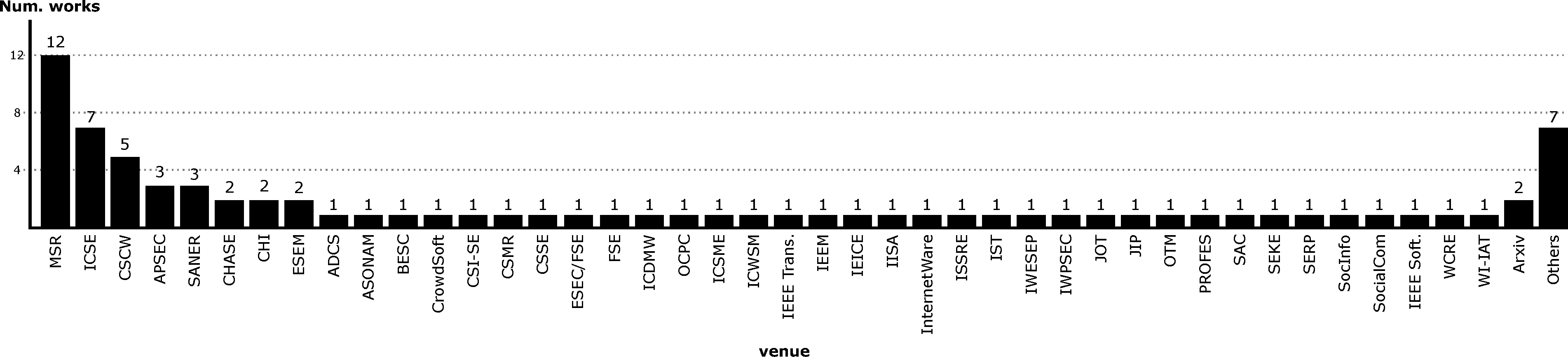
What are the research communities and the publication fora used?
We believe it is also interesting as part of a systematic mapping study to characterize the research community behind the field, both in terms of the people and the venues where the works are being published. According to this, we analyzed the two following dimensions:
- Researchers, which we propose to analyze by building the co-authorship graph of the selected papers. In this kind of graphs, authors are represented as nodes while co-authorship is represented as an edge between the involved author nodes. Furthermore, the weight of a node represents the number of papers included in the set of selected papers for the corresponding author while the weight of an edge indicates the number of times the involved author nodes have coauthored a paper. By using co-authorship graphs, we can apply well-known graph metrics to analyze the set of selected papers from a community dimension perspective.
- Publication fora, which requires a straightforward analysis as we only have to use the venue where each selected paper was published.

Discussion
It’s undeniable the amazing opportunity that GitHub (or more specifically the millions of projects hosted there and all the available data that comes with them) offers to the software research community. Many useful findings have already been reported that I believe can make a significant impact on the way open source projects are managed (hopefully, making them more community-aware 🙂 ).
Still, we have also seen some issues regarding how some of these previous studies have done that could hinder the generalization of the results. I think it’s only fair to finish our metastudy with a list of concerns that we would like to see addressed in the future.
Lack of specific development areas and interdisciplinary studies. Our analysis of areas/topics reveals a lack of works studying GitHub with a more interdisciplinary perspective, e.g., from a political point of view (e.g., study of governance models in OSS), complex systems (e.g., network analysis) or social sciences (e.g., quality of discussions in issue trackers). We also miss works targeting early phases of the development cycle (e.g.s studying requirements and design aspects). Obviously, these kinds of studies are more challenging since there is typically fewer data available in GitHub or needs more processing.
Overuse of quantitative analysis. Right now, a vast majority of studies rely only on the analysis of GitHub metadata. We hope to see in the future a better combination of such studies (typically large regarding the spectrum of analyzed projects but shallow in the analysis of each individual project) with other studies targeting the same research question but performing a deeper analysis (e.g., including also interviews to understand the reasons behind those results) for a smaller subset of projects. We detected some evidences of this shift in the number of works applying longitudinal studies, where we found a positive trend, thus improving the situation detected in OSS by other works.
Poor sampling techniques. We believe that the GitHub research community could benefit from a set of benchmarks (with predefined sets of GitHub projects chosen and grouped according to different characteristics) and/or from having trustworthy algorithms responsible for generating diverse and representative samples according to a provided set of criteria to study. These samples could, in turn, be stored and made available for further replicability studies.
Small datasets size. Most papers use datasets of small-medium size, which are an important threat to the validity of results when trying to generalize them. Also, more than half of the analyzed paper did not provide a link to the dataset they used nor an automatic process to regenerate it, which may also hamper the replicability of the studies. However, it is important to note that the number of works sharing their datasets is increasing over time.
Low level of self-awareness. We believe the limited acknowledgment of their threats to validity (around 34% do not report any) puts the reader in the very difficult situation of having to decide by herself the confidence in the reported results the work deserves. Works reporting partial results or findings on very concrete datasets are perfectly fine but only as long as this is clearly stated. However, we detected an upward trend in reporting threats to validity in recent years.
Need of replication and comparative studies. Clearly urgent since almost none exist at the moment. replicability is hampered by some of issues above and the difficulties of performing (and publishing) replicability studies in software engineering. Comparative studies need to first set on a fixed terminology. Some papers may seem inconsistent when reporting on a given metric but a closer look may reveal that the discrepancy is due to their different interpretation. For instance, this is common when talking about success, popularity or activity in a project (e.g., one may consider a project successful as equivalent to popular, and by popular mean to be starred a lot, while the other may interpret successful as a project with a high commit frequency). Replicability
is also threaten in studies involving user interviews, as the material produced as a result of such interviews is normally not provided.
API restrictions limits the data collection process. GitHub self-imposed limitations on the use of its API hinders the data collection process required to perform wide studies. A workaround can be the use of OAuth access tokens from different users to collect the information needed. An OAuth access token is a form to interact with the API via automated scripts. It can be generated by a user to allow someone else to make requests on his behalf without revealing his password. Still, researchers may need a large number of tokens for some studies. To deal with this issue, we propose that GitHub either lifts the API request limit for research projects (pre-approving them first if needed) or offers an easy way for individual users to donate their tokens to research works they want to support.
Privacy concerns. Data collection can also bring up privacy issues. Through our study, we discovered that GitHub and third-party services, built on top of it, are sometimes used to contact users (using the email they provide in their GitHub profile) to find potential participants for surveys and interviews. This potential misuse of user email addresses can raise discontent and complaints from the GitHub users. Even when it is not clear whether such complaints are reasonable, the controversy alone may hamper further research works and therefore must be dealt with care. As with the tokens before, we would encourage GitHub to also have an option in the user profile page to let users say whether they allow their public data to be mined as part of research works and under what conditions.

Associate Professor at Universitat Oberta de Catalunya and researcher at SOM Research Team, in Barcelona, Spain, he likes investigating on how software is developed, in particular how open-source software is developed and how people collaboratively drives the creation process. He has been working mainly in the area of programming & domain-specific languages, modeling, modernization and model-driven engineering.