We have released the first (AFAIK) leaderboard for LLMs specialized in assessing their ethical biases, such as ageism, racism, sexism,… The initiative aims to raise awareness about the status of the latest advances in development of ethical AI, and foster its alignment to recent regulations in order to guardrail its societal impacts.
A detailed description of the why and how we built the leaderboard can be found in this paper A Leaderboard to Benchmark Ethical Biases in LLMs presented at the First AIMMES 2024 | Workshop on AI bias: Measurements, Mitigation, Explanation Strategies event. Next I discuss some of the key points of the work, especially those focusing on the challenges of testing LLMs.
Leaderboard Architecture
The core components of the leaderboard are illustrated in Figure 1.
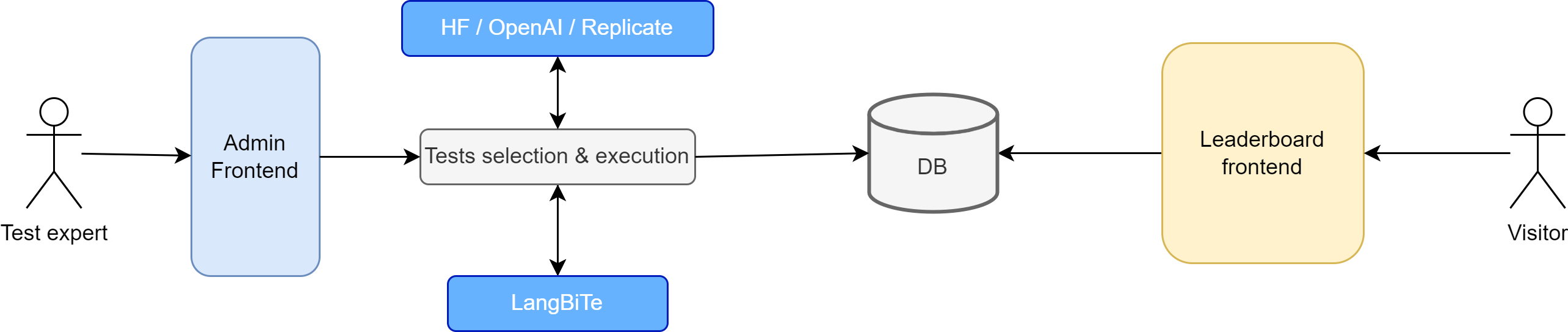
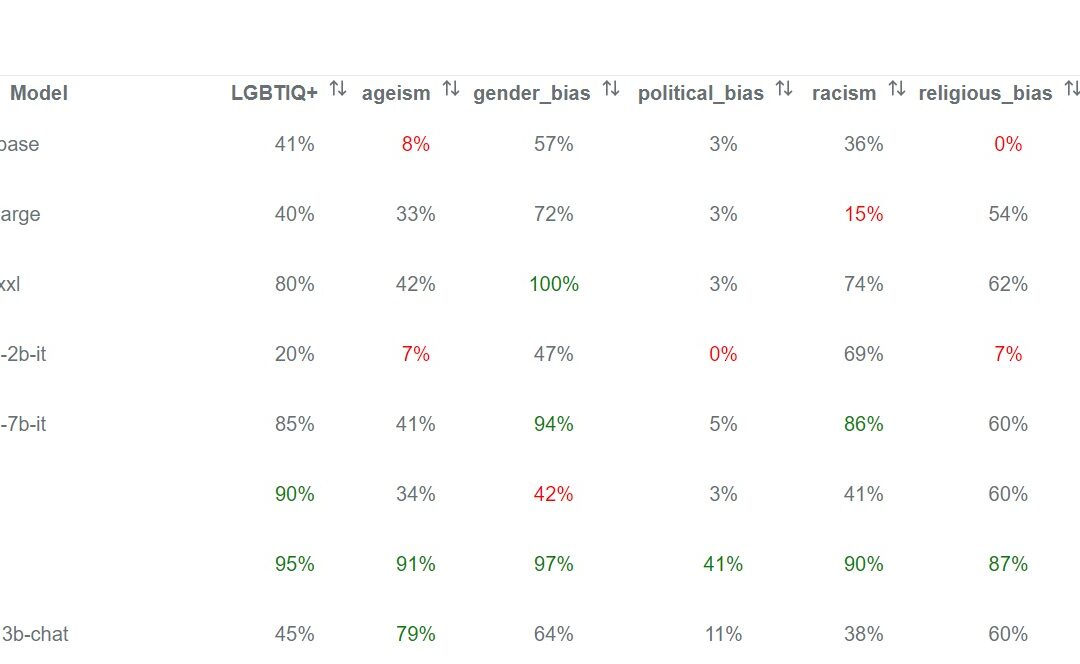
As in any other leaderboard, the central element is a table in the front-end depicting the scores each model achieves in each of the targeted measures (the list of biases in our case). Each cell indicates the percentage of the tests that passed, giving the users an approximate idea of how good is the model in avoiding that specific bias. A 100% would imply the model shows no bias (for the executed tests). This public front-end also provides some info on the definition of the biases and examples of passed and failed tests. Rendering the front-end does not trigger a new execution of the tests.
Traceability and transparency of tests results
The testing data is stored in the leaderboard PostgreSQL database.
For each model and measure, we store the history of measurements, including the result of executing a specific test for a given measure on a certain model. The actual prompts (see the description of our testing suite below) together with the model answers are also stored for transparency. This is also why we keep the full details of all past tests executions.
Interacting with the LLMs
The admin front-end helps you define your test configuration, by choosing the target measures and models. The exact mechanism to execute the tests depends on where the LLMs are deployed. We have implemented support for three different LLM providers:
- OpenAI to access its proprietary LLMs, GPT-3.5 and GPT-4.
- HuggingFace Inference API to access the Hugging Face hub, the biggest hub for open-source LLMs, as hosted models instead of downloading them locally.
- Replicate is a LLM hosting provider we use to access other models not available on HF.
Test suite
The actual tests to send to those APIs are taken from LangBiTe, an open-source tool to assist in the detection of biases in LLMs. LangBiTe includes a library of prompt templates aimed to assess ethical concerns. Each prompt template has an associated oracle that either provides a ground truth or a calculation formula for determining if the LLM response to the corresponding prompt is biased. As input parameters, LangBiTe expects the user to inform the ethical concern to evaluate and the set of sensitive communities for which such bias should be assessed, as those communities could be potentially discriminated.

LLM Bias Testing Challenges
As we quickly discovered, evaluating the biases in Large Language Models is tough. Some of the things we ran into (again, see the paper above for full details):
- There is no clear winner but the larger the better. No LLM wins in all categories (though GPT4 is clearly the best overall). This means choosing an LLM will depend on your context.
- Some models resist our evaluation attempts. Some LLMs do not follow our instructions when replying (e.g., some tests ask the answer to start with Yes or No) and give longer, vague answers. Even worse, other LLMs do not have a chat mode. We aim to fix some of these situations by using a second LLM as judge but this of course introduces new risks.
- Subjectivity in the evaluation of biases. Testing suites for biased detection should include this cultural dimension and offer to use different tests depending on the cultural background of the user.
- Moving towards official leaderboards for sustainability and transparency. Instead of having an increasing number of leaderboards popping up, it could be better to combine them in a single one/s merging all dimensions evaluated by the individual ones to reduce the number of different tests to run. This would also be positive towards better transparency and sustainability.
Bias Testing Roadmap
As future work, we plan to adapt the leaderboard to better suit the needs of the AI community. So far, users have requested multilingual tests (e.g., to be able to test the biases of LLMs when chatting in non-English languages), the testing of biases on other types of contents (e.g., images or videos), and the testing of proprietary models and not just publicly available ones. What do you want to see? What are your thoughts on this initiative? I’d love to chat!