The growing AI market has generated an explosion of libraries, datasets, models and all types of AI-related software artefacts to exploit and serve such markets. Many of them released with open-source licenses to facilitate their reuse and foster collaboration efforts to speed up their development.
As we have done for many other open source communities, understanding and analyzing the collaborations and relationships between such artefacts, their creators and their users will help us to detect opportunities to optimize their development and facilitate its comparison and evolution. This is the goal of a new research line in our team. As a first tangible result, we want to contribute to the research community HFCommunity, an up-to-date relational database built from the data available at the Hugging Face Hub, thus providing queryable data about the repositories hosted in the Hub and the people working on them.
Why Hugging Face?
Hugging Face and, in particular, the Hugging Face Hub have become the default option to host any Machine Learning artefact, from the datasets to train models, to the models themselves and demo applications showing interesting applications that can be built with them.
Similar to how GitHub works, all artefacts can be uploaded to a Git repository on top of which Hugging Face offers some collaboration and execution capabilities. For instance, in the in the last year Hugging Face enabled a feature on the repositories named “Hub Pull requests and Discussions“, which works in a similar way as the issue tracking and pull requests of other code hosting platforms.
What can you find in HFCommunity?
We have collected the information available in the Hub together with deeper data from the Git repository linked to the Hub artefacts so that we can also the code evolution of the artefacts when required. To do this, we have relied on the Hub client library complemented with PyDriller for the inspection of the Git repositories.
The former is provided as a Python library named huggingface_hub. This library is intended to interact with the Hub using Python scripts. However, it also offers the chance to retrieve useful information about all the public repositories.
All this data is then normalized and stored into a relational database. The current schema of this database is the following
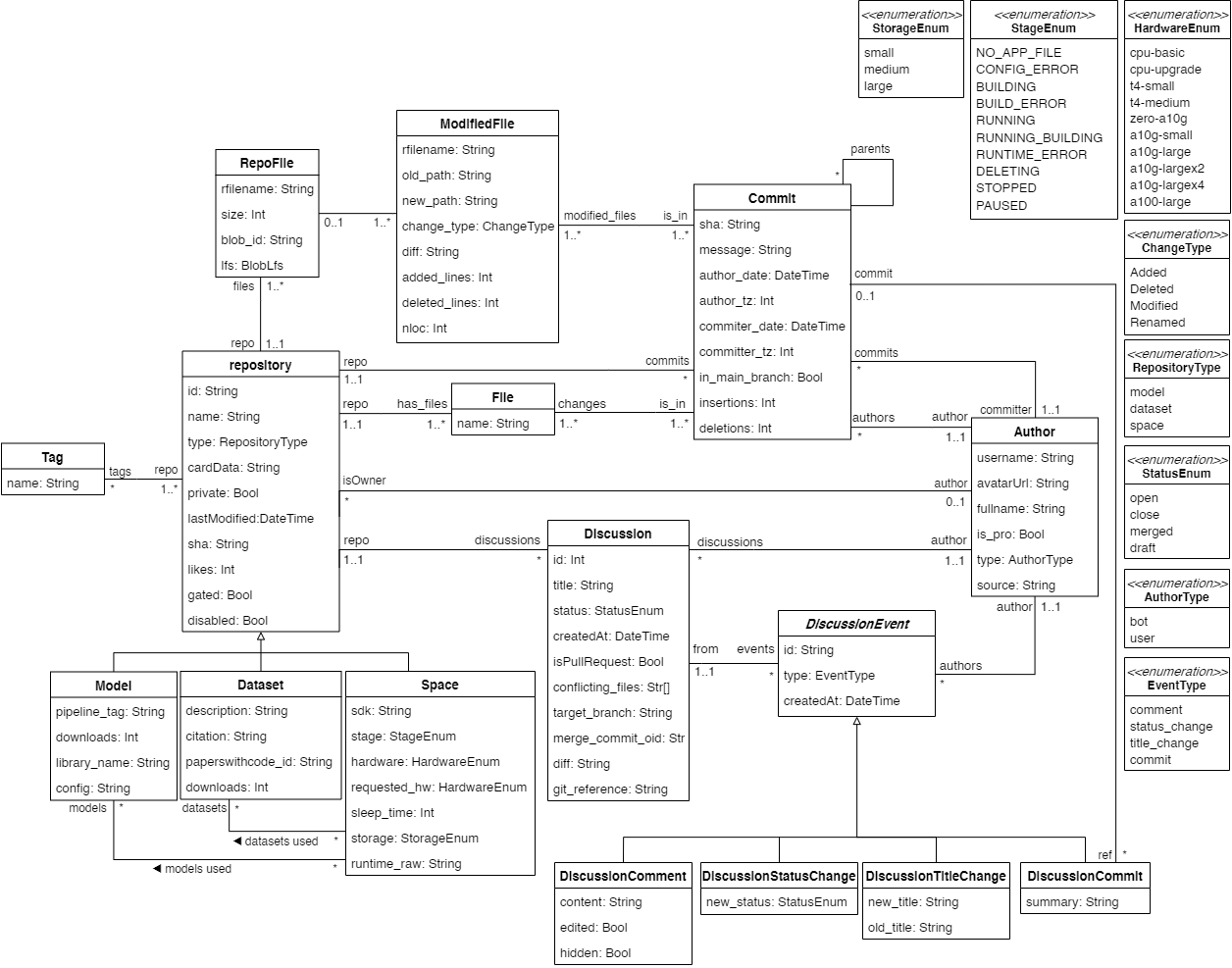
UML conceptual schema of HFCommunity (v1.1)
Given the popularity of SQL, we believe providing the HFCommunity information in a database format will facilitate the analysis of Hugging Face community data by a broad audience.
What can you do with HFCommunity?
In the HFCommunity website, we offer a dump of our database and show some simple metrics to visualize the possibilities of exploitation this data has. For instance, you can check what are the most active organizations and the most popular models, how big are the projects (in terms of number of files), whether they are regularly updated or the Hub is mostly used to drop an initial version for reference purposes, what models are the most used in spaces, whether people actually use the new discussion feature in the Hub, and so on.
But, as we said above, our goal is just to facilitate this information so that anybody can study how AI software is developed. Given the key role of AI in our society, any suggestion on how to improve development of AI software components (e.g. by facilitating strategies to make sure such components better responds to the users’ needs or increasing their chances of long-term survival) can definitely have a huge impact.
We’d be grateful if you let us know what you think about this initiative and how we can make it more useful to you. Leave a comment with your thoughts!
Research Engineer at IN3-SOM Research Team, in Barcelona, Spain. Currently studying a data science master. Interested in open source dynamics and collaboration.