
The development of empirical studies in Open-Source Software (OSS) requires large amounts of data regarding software development events and developer actions, which are typically collected from code hosting platforms. Code hosting platforms are built on top of a version control system, such as Git, and provide collaboration tools such as issue trackers, discussions, and wikis; as well as social features such as the possibility to watch, follow and like other users and projects. Among them, GitHub has emerged as the largest code hosting site in the world, with more than 100 million users and 180 million (public) repositories.
The development of empirical studies in software engineering mainly relies on the data available on code hosting platforms, being GitHub the most representative. Nevertheless, in the last years, the emergence of Machine Learning (ML) has led to the development of platforms specifically designed for developing ML-based projects, being Hugging Face Hub (HFH) the most popular one. With over 600k repositories, and growing fast, HFH is becoming a promising ecosystem of ML artifacts and therefore a potential source of data for empirical studies. However, so far, there are no studies evaluating the potential of HFH for such empirical analysis.
We need your help!
We are currently performing a study to evaluate HFH (more details in the following sections) and its potential as source of data for empirical studies.
As part of this study, we want to better understand what are, in your opinion:
- the essential characteristics of code hosting platforms,
- and what stats of a project you’d like to see when deciding when choosing which projects or libraries to be part of your project when several offer a similar functionaity you need
For this, we created a survey to collect the opinions of developers and researchers. If you are a developer using a code hosting platform frequently, or a researcher of the empirical studies (EMSE) or mining software repositories (MSR) areas, we would be very grateful if you could answer the survey (click here to answer).
And if, on top of answering the interview, you’d be open to have a short interview with us to elaborate on your opinions, we would be very grateful. In the last question, leave your email (or just contact us anytime) if you agree to have an interview.
So… What’s Hugging Face Hub?
Many of you may know this emergent platform, but for those who don’t, HFH is a Git-based online code hosting platform aimed at providing a hosting site for all kinds of ML artifacts, namely: (1) models, pretrained models that can be used with the Transformers library; (2) datasets, which can be used to train ML models; and (3) spaces, demo apps to showcase ML models.
As of November 2023, the platform hosts more than 625k repositories, and this number is growing fast. To illustrate the growing evolution of the platform, the following figures illustrate the natural and cumulative growth of new project registrations by month in HFH, respectively.
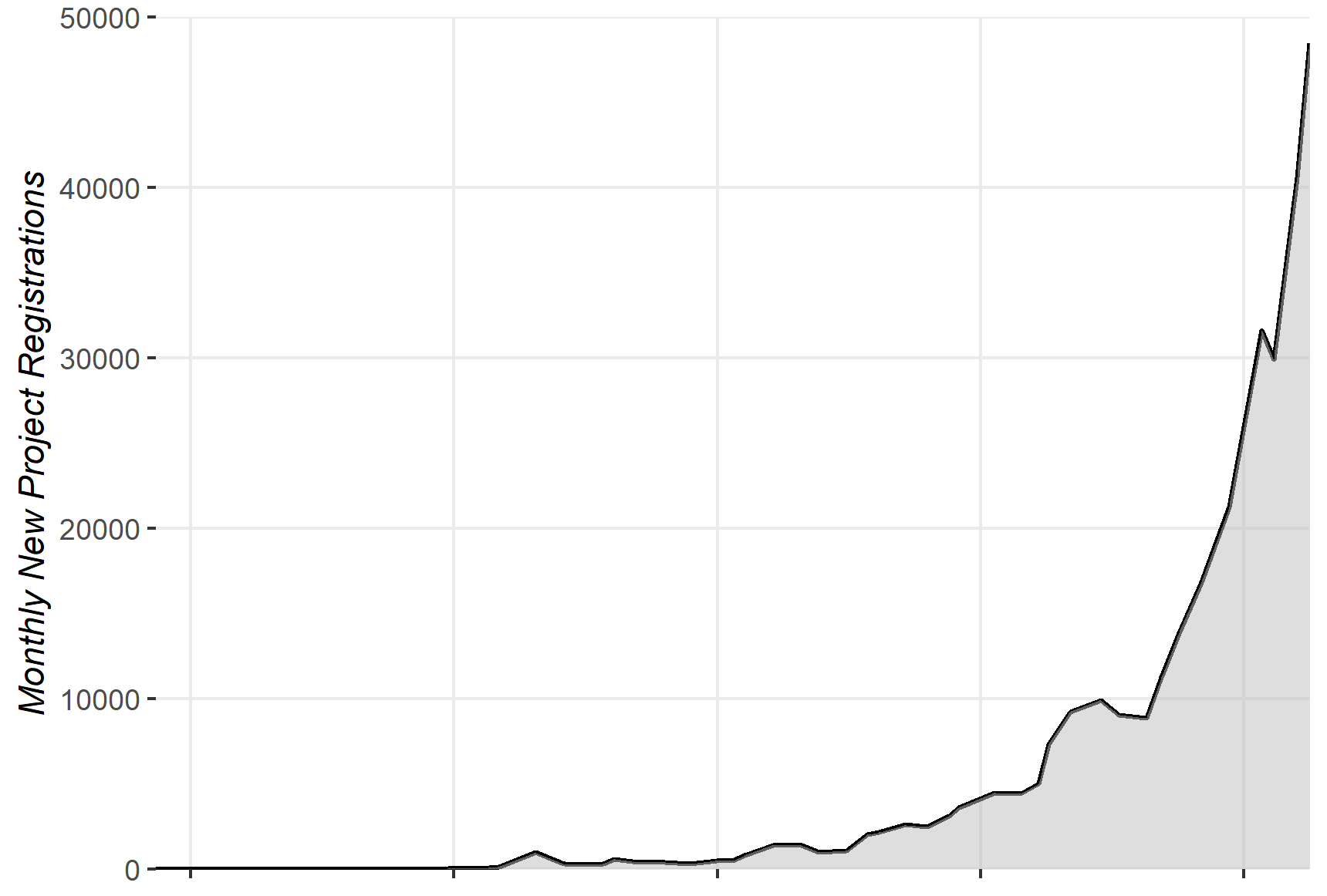
Number of project registrations per month in HFH
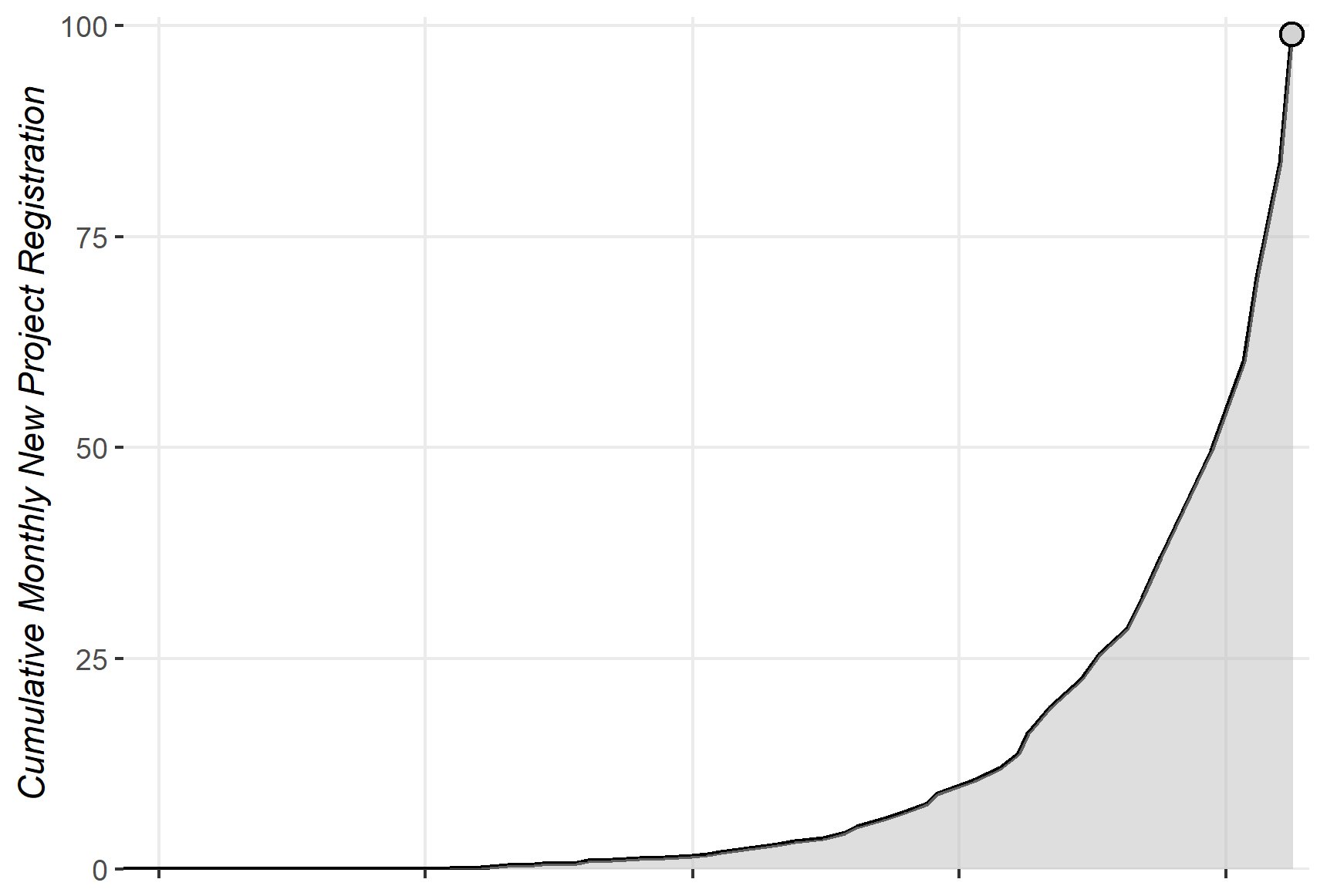
Cumulative number of projects in HFH
HFH has been evolving and incorporating features which are typically found in GitHub, such the ability to create discussions or submit pull requests enabling more complex interactions and development workflows. This evolution, its growing popularity and the ML-specific features make HFH a promising source of data for empirical studies. Although the usage of HFH in empirical studies is promising, the current status of the platform may involve relevant perils.
Our proposal
In ESEM ’23 we presented a registered report with the purpose of evaluating the potential of HFH for empirical studies (click here to read the full report). The goal of our registered report is to assess the current state of HFH and analyze its adequacy to be used in empirical studies. For this, we proposed two research questions. The first one goes as:
- What features does HFH provide as a code hosting platform to enable empirical studies?
This RQ is proposed to properly comprehend the key features that characterize HFH both for individual projects (i.e. features oriented towards end-users planning to use HFH for their software development projects) and at the platform level (i.e. to facilitate the retrieval and analysis of global HFH usage information). This analysis will allow characterizing the platform and identifying potential use cases for empirical studies. Hence, we subdivided this research question into two:
-
- What features HFH offers to facilitate the collaborative development of ML-oriented projects?
- What features HFH offers at the platform level to facilitate access to the hosted projects’ data?
The first one performs an exploratory study of the features offered by HFH to projects hosted in the platform. In this RQ, we focus on the features serving project development tasks, such as pull requests for managing code contributions or issue trackers for notifying bugs or requests. To this aim, we plan to study current code hosting platforms to define a feature framework to be used as a reference framework to analyze the platform. The second one’s purpose is to examine the features provided by HFH aimed at retrieving its internal data, derived from the activity of projects hosted in it.
The second research question is defined as:
- How is HFH currently being exploited?
In this RQ we are interested in studying how HFH is so far being used at platform and project levels. In each level, we will analyze the data within two perspectives: volume and diversity. To measure the volume we define quantitative variables, such as the number of repositories and users at platform level; or the number of files, contributors and commits at project level. On the other hand, to measure diversity we define categorical variables, such as the programming languages used in the repositories or the type of contributions (i.e., issues or discussions) in the projects. Following the level identification, we have subdivided this research question into two:
-
- What is the current state of the platform data in HFH?
- What is the current state of the project data in HFH?
The first one analyzes the platform as a whole while the second one explores the usage of HFH at project level being the goal to characterize the average (or averages if we detect different typologies) project on HFH via the analysis of their number of files and commits, number of users, its temporal evolution, etc.
Addressing the Research Questions
To address our research question, we plan to conduct a qualitative and quantitative analysis of HFH. The former will address RQ1, as it will focus on identifying the features of HFH and the options available to retrieve HFH data. The latter will address RQ2, and will allow us to analyze the data available in HFH via the reported data retrieval solution.
Qualitative Analysis
During the qualitative analysis we will build a feature framework aimed at identifying which characteristics define a code hosting platform. The framework is built by analyzing different code hosting platforms and identifying the features offered by each platform. The features extracted from this process rely on authors’ experience on the platform, the platform documentation and usage and literature. We plan to revise a number of platforms, leveraging on existing literature. The result is a superset of features which will be backed by the literature from relevant venues to underline the importance of some specific features in empirical studies. A preliminar version of our framework can be depicted as:
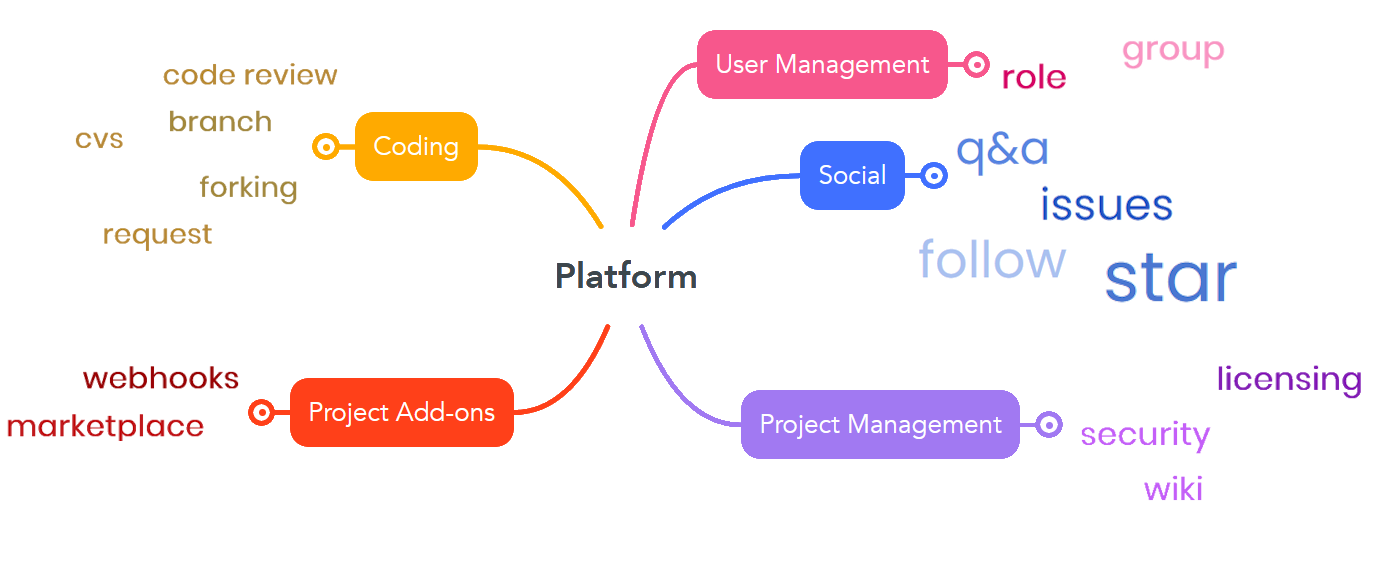
Feature framework
Besides the literature, we plan to validate this framework by conducting semi-structured interviews with relevant actors of each analyzed platform. We are currently in this phase, where we are collecting the input of actors of such platforms.
Once our framework is validated, it will characterize HFH in terms of features, and will allow us to analyze their importance in the context of empirical studies. We plan to study the intersection of these features with the ones offered by other code hosting platforms. The intersection can bring three scenarios:
- Shared features, which would enable replicating in HFH empirical studies performed in other platforms.
- Features not available in HFH, where we will study its impact and significance with regard to existing empirical studies.
- Exclusive features of HFH, where we can discuss opportunities where unique HFH features may open new applications for empirical studies.
RQ1.2 targets the retrieval data process from HFH, we plan to compare the means offered by the platform with those available in other code hosting platforms. We define the easiness of data retrieval with different aspects:
- Usability of the mechanisms, which values the amount of existing solutions, such as APIs or datasets.
- Accessibility of such solutions, whether they are open to everyone or if they require some sort of login, for instance.
- Limitations, such as a token-based restriction.
- Recentness of the solutions, which focus on whether there is a temporal gap between the retrieved information and the platform data at the moment of extraction.
Quantitative Analysis
In the quantitative analysis we will examine the HFH data to provide an overview of the current usage of the platform, performed at platform and project level. The former will show the actual usage of the features identified in the previous research question and conclude on the level of exploitation of such features. The latter will give an insight of how the development process is currently carried out in HFH, thus favoring the comprehension of why the users use this platform. To address this analysis we leverage on the data provided by HFCommunity.
We define quantitative variables to analyze the platform and the repositories. The Platform category is designed to characterize the HFH environment. The HFH platform is specifically designed for ML-based artifacts, thus the platform aspects may differ, such as having repositories designed for each type of ML artifact. Regarding the Project category, we will intend to give an insight on the status of the repositories. Empirical analysis usually rely on a reduced subset of the repositories in a code hosting platform. Therefore, we find appropriate to perform an analysis from a repository perspective and identify whether there is a way to select prolific repositories to perform empirical analysis as it is done on other code hosting platforms. Some example of variables of each level can be visualized as:
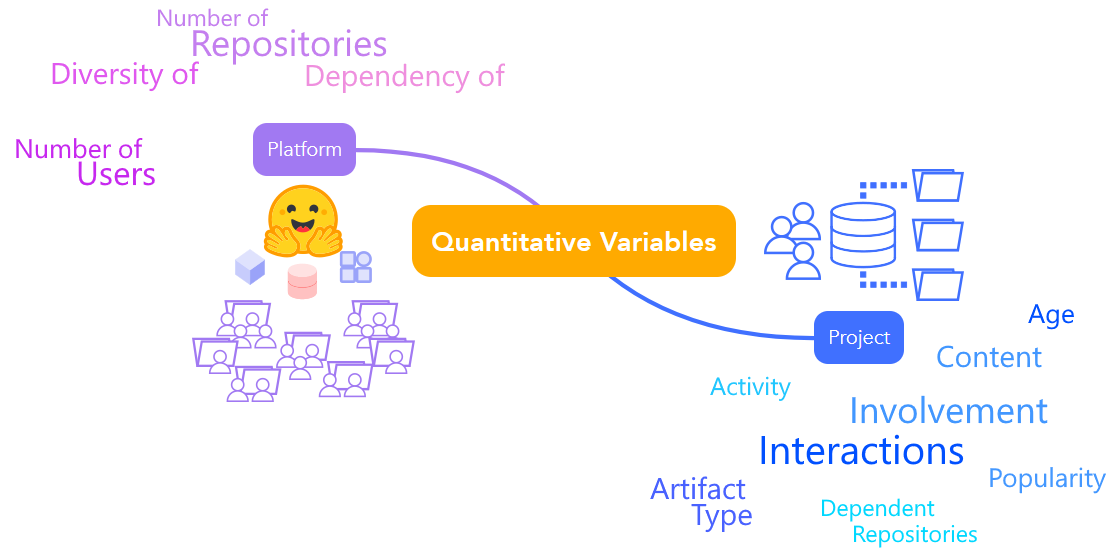
Quantitative variables
Conclusion
In this article, we presented our proposal for a study of the suitability of HFH for empirical studies. The study comprises a feature-based framework comparison to characterize the HFH functionality together with an analysis of the mechanisms to retrieve information on how such features are used. This allows evaluating the suitability of HFH from a feature availability perspective. Besides this feature-level study we propose to conduct a second one, more quantitative one, based on the study of volume and diversity of the data stored on the HFH. We conduct this study both at the platform and project-levels, looking at the overall volume and richness of the data and on how the average project uses the platform.
Beyond a deeper understanding on how collaborative de- velopment of ML-related projects takes place on the HFH, the conclusion of this report is expected to be a discussion on whether HFH can be a suitable data source to perform empirical studies. Also, given that empirical studies usually focus on a specific characteristic of code hosting platforms, beyond a boolean answer, the goal is to discuss what types of empirical studies could benefit from HFH data, either as a standalone data source or in combination with GitHub or other data sources.
Research Engineer at IN3-SOM Research Team, in Barcelona, Spain. Currently studying a data science master. Interested in open source dynamics and collaboration.