
In the last years, GitHub has become one the most popular platforms (if not the most) to develop and promote open-source projects. With more than ten millions of repositories (and growing, though quite a few of them are not real projects), GitHub gathers many of the important projects in the OSS scene. Thus, we believe that the analysis of GitHub projects can provide some interesting findings on how the OSS communities work. As part of our research work in this area, we would like to share some the interesting data we are collecting. Today we focus on how people/projects use the labels to tag the issues in GitHub projects.
GitHub provides issue-tracking capabilities, which allows developers to manage issues regarding the development of the software. As a way to categorize or group issues, they can be labeled, thus facilitating their management. Curiously enough, developers use issue labels in a pretty particular way. While GitHub provides a set of default labels (i.e., bug, duplicate, enhacenment, invalid, questions and wontfix) it turns out that they fall short in most cases. In this blog post we (Belen Rolandi, Valerio Cosentino, Jordi Cabot and me) show some figures that illustrates the real use of labels in GitHub.
We have analyzed the issue labels used in a random sample of 55622 GitHub projects. We generated a tag cloud by collecting all the labels of every issue and then applying some preprocessing on it. The preprocessing consisted in removing spaces and grouping under a unique identifier labels that have the same meaning (e.g., high-priority and priority:high, doc and documentation, etc.). For the sake of clarity, the size of the words is in logarithmic scale.
 .
.
The following bar graph gives more specific numbers on the most used tags and how many issues are tagged with them: 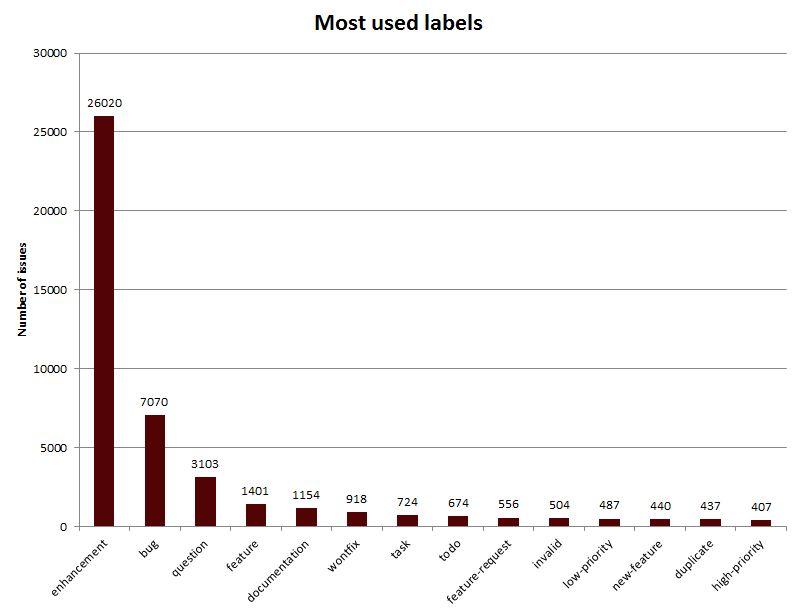
The results show that the three most used labels across GitHub repositories are part of the default ones provided by the platform (i.e., enhancement, bug and question). However, custom labels are also placed in interesting positions. For instance, the labels feature and documentation are placed in fourth and fifth position, which may suggest the importance of issues on these topics in the development of GitHub projects. Note that labels to manage issue priority are also included in this ranking (e.g., low-priority and high-priority).
The above graphics show the most popular labels but is this label mechanism something that most projects use? The following bar graph shows the number of different labels used in every project. As you can see most projects only use one or two different labels.
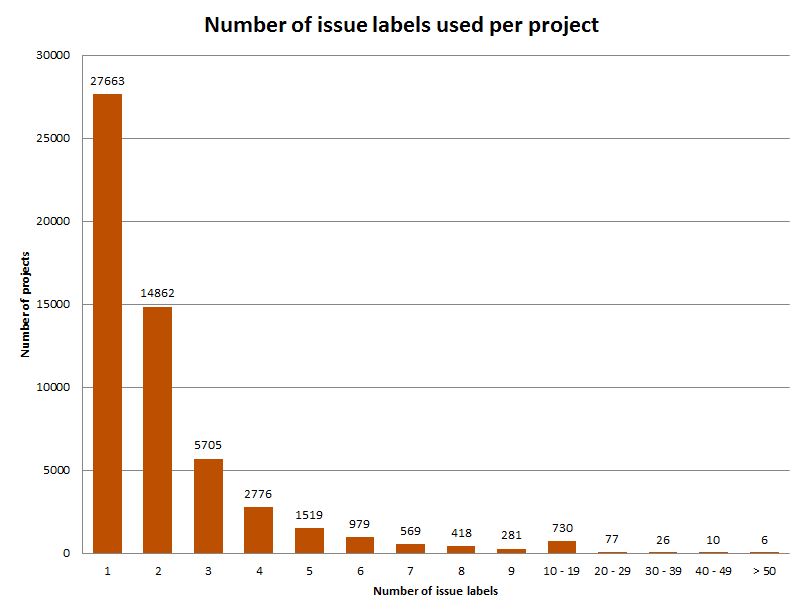
Although these are just some basic metrics, it already suggests that the analysis of the label mechanism in OSS projects could bring up some interesting questions. For instance, do GitHub projects hardly use labels because they are not useful or because they do not know how to benefit from them?, are they flexible enough? should they be normalized and given standard semantics across projects? can they be used to identify the most active users or to classify the status of a given project (depending, for instance, on whether most issues refer to bugs or to enhancements).
I’m also adding here a couple of short presentations we’ve doing on this topic. The presentations include some additional data points you may find interesting as well:
- (SANER’15 tool paper) GiLA: Analyzing the use of issue labels in GitHub projects: What can issue labels teach you about your project? Three simple yet powerful visualizations to better understand WHO is doing WHAT
- (SANER’15 new ideas research paper) Exploring the Use of Labels to Categorize Issues in Open-Source Software Projects: there is little empirical evidence to confirm that taking the time to categorize new issues has indeed a beneficial impact on the project evolution. In this paper we analyze a population of more than three million of GitHub projects and give some insights on how labels are used in them.

Associate Professor at Universitat Oberta de Catalunya and researcher at SOM Research Team, in Barcelona, Spain, he likes investigating on how software is developed, in particular how open-source software is developed and how people collaboratively drives the creation process. He has been working mainly in the area of programming & domain-specific languages, modeling, modernization and model-driven engineering.