Open data: are we there yet?. This was the title of a personal reflection on the present and future of open data, published in the blog of the Internet Interdisciplinary Institute. There, I argued that while the number of open data resources keeps growing at a fast pace (the European data portal, which aggregates all open data initiatives in Europe, links to over 400.000), regular citizens hardly benefit from them. As I said there, my parents cannot really use any of them: they do not natively read JSON or CSV, cannot call APIs or open XML files, just to mention some of the data formats used to publish the data
Open Data may be open but has not been really opened to the citizens Click To TweetWhat can we (developers / engineers) do help fixing this? At the very least we could make sure the datasets we publish satisfy these following characteristics for a usable open data infrastructure:
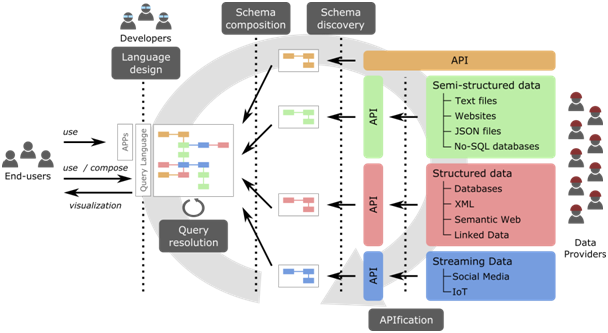
- Unify the publication format of open data to simplify the generic manipulation of any resource. Even more, we propose to use REST-based APIs as the default format to publish and give access to resources. This standard is the most common in all other kinds of data resources published by private companies (e.g. ProgrammableWeb lists more than 20000 APIs for all kinds of domains, from nutrition to weather to transportation…), which would simplify combining public and private open data.
- Clear definition of the type and schema of the data behind each resource. Administrations need to do a better job in describing what kind of data is available behind each resource. And in a precise and machine-readable way that can be then used to automatically analyze the data. If needed, this schema can also be automatically discovered
- Be honest with the quality of the data you’re providing. Publishing the data is not enough. You need also to explain the quality of such data. How “fresh” is it? How often is updated? How sure you’re about the reliability of the data itself?. These aspects are important when deciding what data source to use in a given app.
- Link your open data. Any meaningful open data application typically requires the combination of 2 or more data sources. Maybe even from different providers. As for the discovery part, potential compositions can be automatically detected but data owners should provide explicit links between their datasets to simplify building apps that select, combine and merge data.
- Provide conversational interfaces to access the data. Previous requirements mainly concern the organization of the data in the back-end but, once organized, we still need to simplify the way a citizen can browse it. Chatbots could be a good solution. The user would be able to ask questions in natural language and the bot would then try to find the right answer exploring the data on behalf of the citizen.
If you’re interested in addressing any of these roadblocks for open data, read the full reflection or explore our “Open data for All project” (depictes also in the image heading this post) where we provide a variety of tools to automatically discover and compose OpenAPI datasets.